
Project Updates
Hello! Long time no see :-)
But no updates did not mean nothing happened. Quite the opposite: FutureSDR got quite a bit of an overhaul and should have much cleaner internals now.
The user-facing API stayed fairly untouched, but the runtime changed a lot. A bunch of ugly hacks and annoying limitations are gone now. The new runtime should provide a much better compromise between ergonomics, type-safety, and performance.
Why should you care? If you mostly build flowgraphs from existing blocks, you probably shouldn’t. If you are into custom blocks, custom buffers, hardware drivers, or WASM applications, this should make life nicer: fewer weird runtime APIs, more type checking, less boxing, and a clearer path for doing things without fighting the framework or the Rust language.
Individual buffers, schedulers, and blocks still have to be tuned and polished, but the core runtime abstractions now feel like they are landing in the right place. Hopefully, future work should be more local and focused instead of rewriting half the runtime again. Famous last words, obviously.
What follows is a brief, incomplete overview.
Stream Ports
Stream ports used to be an enum with two options: normal CPU buffers and everything else.
/// Buffer writer
#[derive(Debug)]
pub enum BufferWriter {
/// CPU implementation
Host(Box<dyn BufferWriterHost>),
/// Custom buffer for use with accelerators
Custom(Box<dyn BufferWriterCustom>),
}That worked, but it definitely wasn’t a good solution:
- dynamic dispatch to access buffers
- sample types were not reflected in the port type (no compile-time type-checking for stream connections)
- custom buffers needed a custom API and that means downcasting
Today, stream buffers are normal fields on the block struct. For example, the current NullSource looks like this:
#[derive(Block)]
pub struct NullSource<T: CpuSample> {
#[output]
output: circular::Writer<T>,
}So inside work() the block gets typed access to its actual buffer implementation.
And if a block wants a GPU buffer, an in-place buffer, a DMA buffer, or something completely different, it can use that concrete API directly.
Buffer Trait Structure
The old enum also implied that there was one blessed “host buffer” interface. Adding another CPU-ish API, like in-place buffers, meant extending the enum inside FutureSDR itself. Not very plugin-friendly.
Now readers and writers share only the tiny bit of API the runtime needs to connect and shut them down. Roughly:
pub trait BufferWriter {
type Reader: BufferReader;
fn init(&mut self, block_id: BlockId, port_id: PortId, inbox: BlockInbox);
fn validate(&self) -> Result<(), Error>;
fn connect(&mut self, dest: &mut Self::Reader);
fn notify_finished(&mut self) -> impl Future<Output = ()>;
// ...
}Notice what is not there: no slice(), no produce(), no assumption that this is CPU memory.
Those methods live on the buffer families that actually support them.
For normal CPU buffers, there is a dedicated trait:
pub trait CpuBufferWriter: BufferWriter + Default {
type Item: CpuSample;
fn slice_with_tags(&mut self) -> (&mut [Self::Item], Tags<'_>);
fn slice(&mut self) -> &mut [Self::Item];
fn produce(&mut self, n: usize);
// ...
}That means blocks can be generic over the CPU buffer implementation.
#[derive(Block)]
pub struct NullSource<T: CpuSample, O: CpuBufferWriter<Item = T> = DefaultCpuWriter<T>> {
#[output]
output: O,
}Yes, that type signature looks a bit involved. But it allows us to instantiate the block with any buffer type that implements the normal CPU interface (circular, slab, and host-to-device parts of custom buffers), and the common user-facing case still looks fine:
let mut fg = Flowgraph::new();
// This uses NullSource<u8, DefaultCpuWriter<u8>>.
let src = NullSource::<u8>::new();
let head = Head::<u8>::new(123);
let snk = NullSink::<u8>::new();
connect!(fg, src > head > snk);
Runtime::new().run(fg)?;Sample Lifetimes
Another evil API from the old implementation: stream slices had lifetime and ownership hacks.
impl StreamInput {
pub fn slice<T>(&mut self) -> &'static [T] {
self.slice_unchecked()
}
// ...
}Returning &'static here was obviously not exactly the right thing to do :-) And Rust was no longer able to help with mistakes like this:
let samples = sio.input(0).slice();
assert!(!samples.is_empty());
sio.input(0).consume(1);
println!("{:?}", samples[0]);So we had to add manual guard rails to stop users from doing such things. However, that feels like working around the borrow checker and not letting it help.
Now the slice comes from the actual buffer field, with a normal borrow tied to &mut self:
pub trait CpuBufferReader: BufferReader + Default {
type Item: CpuSample;
fn slice(&mut self) -> &[Self::Item];
// ...
}Much less potential to shoot oneself in the foot.
Block Macro
Putting stream ports directly into the block struct is great, but it needs some glue so the runtime can discover and connect those ports.
That glue is generated by the new #[derive(Block)] macro.
The macro implements the internal KernelInterface: stream port lists, init/validation, connection hooks, message ports, and the boring-but-important bits you do not want to write by hand every time.
It also handles message ports. For example, the current MessageSink is:
#[derive(Block)]
#[message_inputs(r#in)]
pub struct MessageSink {
n_received: u64,
}
impl MessageSink {
async fn r#in(
&mut self,
io: &mut WorkIo,
_mo: &mut MessageOutputs,
_meta: &mut BlockMeta,
p: Pmt,
) -> Result<Pmt> {
match p {
Pmt::Finished => io.finished = true,
_ => self.n_received += 1,
}
Ok(Pmt::U64(self.n_received))
}
}The block author writes the important functions. The macro does the plumbing.
Message Inputs
Speaking of message ports: the old handler representation was another thing that could cause headaches when looking at the code.
type HandlerFuture<'a> = Pin<Box<dyn Future<Output = Result<Pmt>> + Send + 'a>>;
pub struct MessageInput<T: ?Sized> {
name: String,
finished: bool,
#[allow(clippy::type_complexity)]
handler: Arc<
dyn for<'a> Fn(
&'a mut T,
&'a mut WorkIo,
&'a mut MessageIo<T>,
&'a mut BlockMeta,
Pmt,
) -> HandlerFuture<'a>
+ Send
+ Sync,
>,
}This came from storing async handler functions in a vector. Which sounds reasonable until every handler call needs boxing, a closure, and dynamic dispatch.
The macro now generates a dispatcher instead. Given this block:
#[derive(Block)]
#[message_inputs(my_handler)]
pub struct MessageSink {
n_received: u64,
}
impl MessageSink {
async fn my_handler(
&mut self,
io: &mut WorkIo,
_mo: &mut MessageOutputs,
_meta: &mut BlockMeta,
_p: Pmt,
) -> Result<Pmt> {
self.n_received += 1;
Ok(Pmt::U64(self.n_received))
}
}The generated KernelInterface contains a match on the PortId:
impl KernelInterface for MessageSink {
async fn call_handler(
&mut self,
io: &mut WorkIo,
mo: &mut MessageOutputs,
meta: &mut BlockMeta,
id: PortId,
p: Pmt,
) -> Result<Pmt, Error> {
let ret: Result<Pmt> = match id.name() {
"my_handler" => self.my_handler(io, mo, meta, p).await,
_ => return Err(Error::InvalidMessagePort(BlockPortCtx::None, id)),
};
ret.map_err(|e| Error::HandlerError(e.to_string()))
}
// ...
}No boxed future. No allocation. No mystery function object. Just a match statement to dispatch the handler call.
Async Trait
FutureSDR’s central Kernel trait used to rely on async_trait:
#[async_trait]
pub trait Kernel: Send {
async fn work(
&mut self,
_io: &mut WorkIo,
_s: &mut StreamIo,
_m: &mut MessageIo<Self>,
_b: &mut BlockMeta,
) -> Result<()> {
Ok(())
}
// ...
}async_trait is super useful, but it hides a cost: the async method becomes a boxed dyn Future.
That means allocation and less room for the compiler to see through the call.
If your work() function never actually awaits, you still pay for the abstraction.
The current Kernel trait uses return-position impl Future instead:
pub trait Kernel {
fn work(
&mut self,
_io: &mut WorkIo,
_mo: &mut MessageOutputs,
_b: &mut BlockMeta,
) -> impl Future<Output = Result<()>> {
async { Ok(()) }
}
// ...
}And as a block author, you can still write the more pleasant version with async:
impl Kernel for MyBlock {
async fn work(
&mut self,
io: &mut WorkIo,
mo: &mut MessageOutputs,
meta: &mut BlockMeta,
) -> Result<()> {
// do radio things
Ok(())
}
}So async work() is now much closer to a zero-cost abstraction.
If there is no await, the compiler has a chance to inline the code.
Non-Send Blocks
The old model did not have a nice way to mix Send and non-Send blocks.
Normal native blocks had to be Send, while WASM lived in its own non-Send world.
That led to two limitations:
- CPU blocks and buffers had to be thread-safe even when they only ever ran on one executor thread.
- WASM blocks could not be distributed across workers, because a non-
Sendblock cannot simply be created on one thread and moved to another later.
Local Domains
Local domains fix the first problem and give us a nicer abstraction for thread-affine things in general.
A flowgraph can create a local domain, then add blocks through closures.
The closure runs inside that domain, so the block can contain non-Send state that never leaves its home thread/worker.
let mut fg = Flowgraph::new();
let local = fg.local_domain()?;
let src = fg.add_local(local, || {
VectorSource::<u8, LocalCpuWriter<u8>>::new(vec![1, 2, 3, 4])
});A normal VectorSource can be Send.
But this one uses LocalCpuWriter, which is not thread-safe and, therefore, intentionally non-Send.
Yet, since the block is constructed inside the local domain and has no chance to ever leave it, that is fine and we can use the more performant buffer implementation.
The nice part is that block implementations do not need duplicate Send and non-Send versions.
The core traits are local by default, and Send capability is added automatically when the type and its futures support it.
pub trait SendKernel: Kernel<BlockOn: Send> + Send
where
Self: Kernel<work(..): Send, init(..): Send, deinit(..): Send>,
{
}That return-type-notation syntax is still nightly-only, which is why FutureSDR currently uses nightly.
But it lets us express exactly what we mean: this kernel value is Send, and the futures returned by its lifecycle methods are Send too.
Without that blanket implementation, we would need duplicate block implementations that do the same work with different trait bounds, which would be annoying.
WASM Scheduler
The same abstractions also helped the WASM side.
There is now a worker-backed WasmScheduler that can run blocks on multiple web workers.
The runtime default on WASM still uses WasmMainScheduler on the browser main thread, but applications can opt into the worker scheduler when they want to offload and distribute DSP to web workers.
Right now, normal blocks are distributed to workers statically when the flowgraph starts. There is no dynamic load balancing yet, so FutureSDR does not move blocks around at runtime. That should be possible later, but the first goal was getting the runtime API clean and working.
The browser still has one big gotcha: waking async Rust futures across web workers is not as smooth as waking things inside one executor. If a block on worker A produces samples and a block on worker B should wake up, normal browser async plumbing does not give us the same nice cross-thread wakeup story we get natively.
So the current worker executor uses queues and a small polling/yielding loop. It is not the final form, but it works and allows some more complex applications.
The browser-native solution would use web worker message passing.
But that would probably mean more WASM-specific runtime code instead of “just cross-compile to wasm32-unknown-unknown”.
Maybe we’ll find a good abstraction that doesn’t complicate things too much.
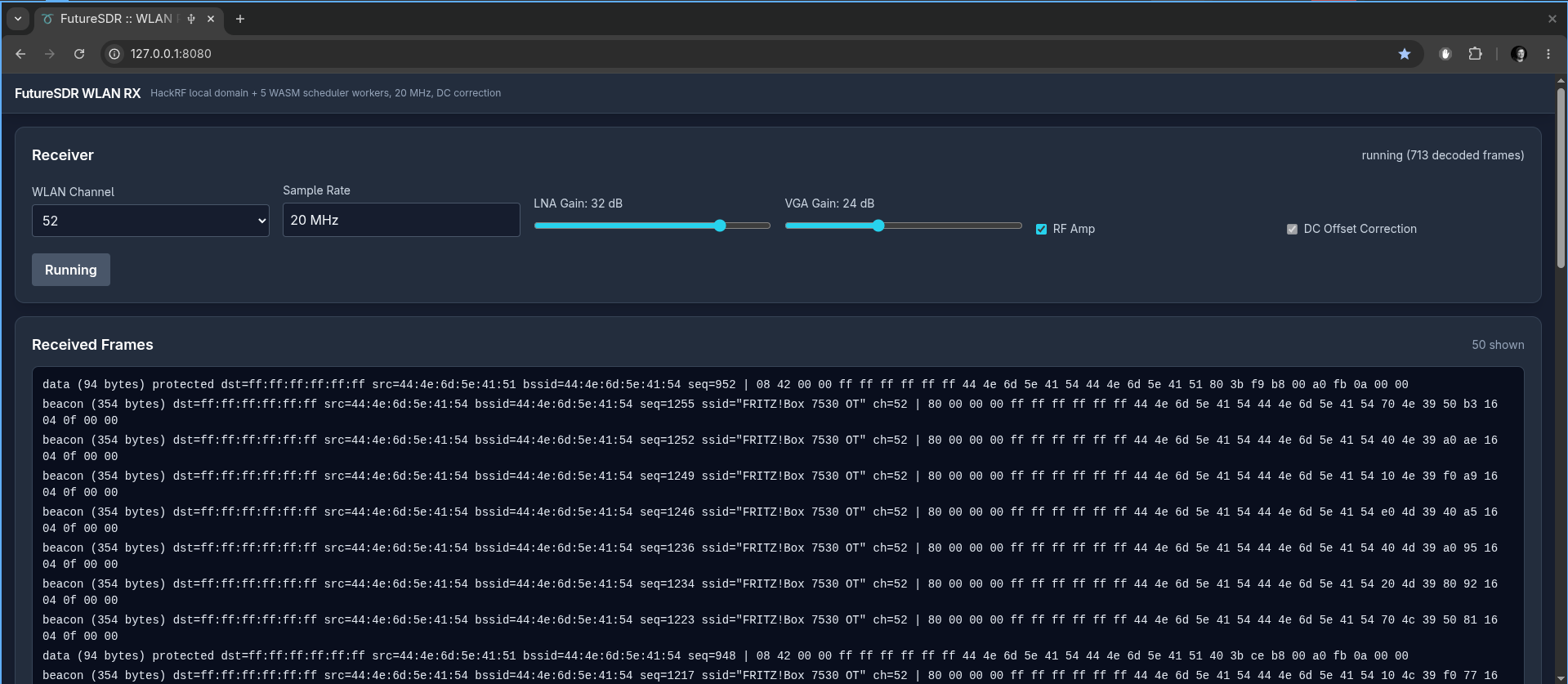
If you want to give things a try, there are WASM examples for the HackRF: Spectrum display, ZigBee receiver, and WLAN receiver.
What’s Next
The next phase is (hopefully) less rewriting the runtime and more focused on individual components.
Some things I have in mind:
- Seify async API: give the SDR hardware abstraction a proper API pass and add async driver support. This should allow browser/WASM drivers, which are inherently async.
- Buffer and block performance: tune the concrete implementations now that the abstractions are less haunted.
- Buffer trait hierarchy: add clearer trait bounds for things like multiple readers and wrap-around buffers, so blocks can ask for what they actually need.
- WASM ergonomics: keep improving the worker-backed scheduler story, including better setup and eventually smarter load distribution.